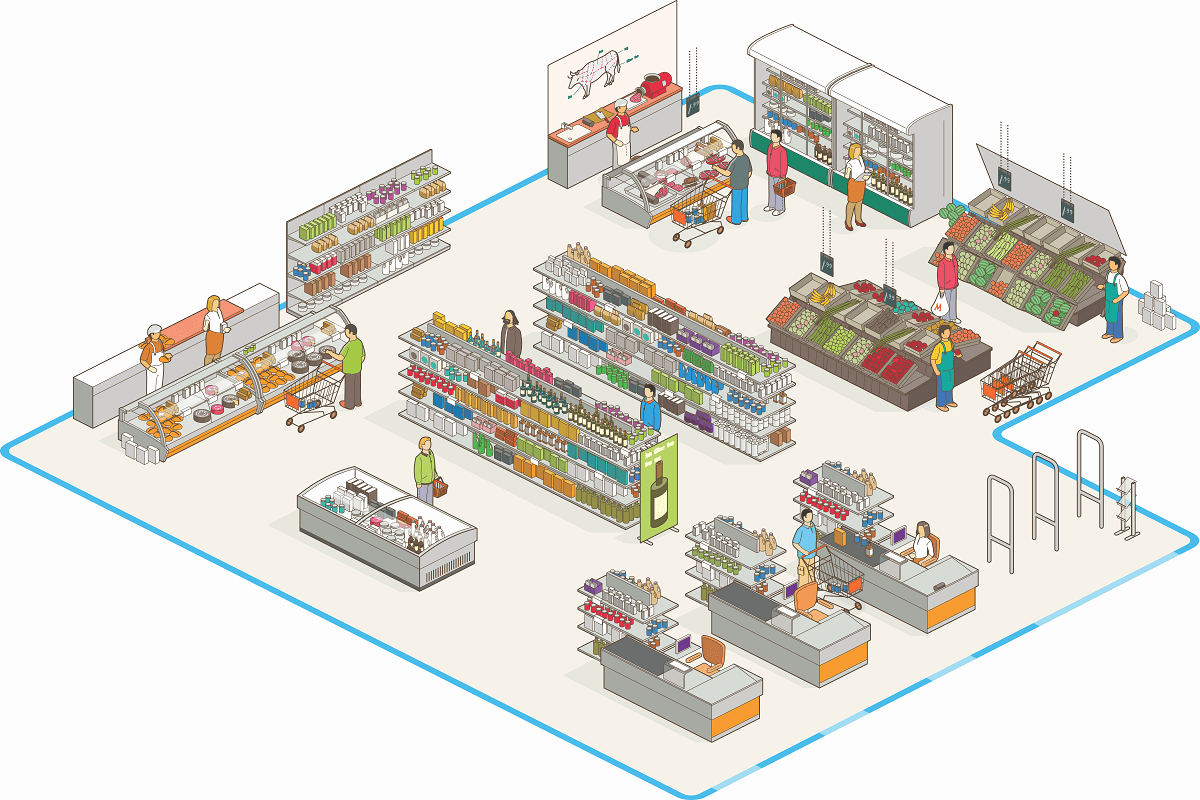
If you have ever struggled with:
inefficient retial layouts,
low inventory turnovers,
or nonstrategic product placement,
then click through below!
Watch Me!
Intro
Looking at the image, we can see how an average retail store layout currently exists. Retailers are busy
engaging with clients and having excellent customer service that it becomes a challenge and a cost to
hire another employee to track customer foot traffic. You may have have had first-hand experience from
this symptom as a customer struggling to find your product.
To help these retailers, we set out to create a software package that takes retail store video as input
and produces useful information about the foot traffic and flow as output. Using this solution will help
retailers maximize its revenue per square foot and be able to track visibility of its product
promotions.
Why "The Floor Is Lava": The name "The Floor is Lava" comes from the visual effect of the heatmap that
makes it appear that the floor is lava.
Project Evolution
From the start, we knew what project we wanted to do, and we talked about which skills each of us could
bring to the table. Feeling that we could pull this off, all four of us began researching computer
vision, image processing, and the ethics of our project idea. Issues were brought to our attention that
led us to shy away from methods, such as facial recognition, that produced personally identifiable
information from the images.
After the first architectural review, we began to experiment with all the methods we had
uncovered and tested their ability to meet our needs. We picked a single method and Duncan and Gabriella
began to iterate on it to meet our needs. Meanwhile, Nick collected sample footage from the Untitled
Fashion Show, and Michael began to put together the project website you see here. Now that we were
writing code that would become part of the final project, documentation became an important focus.
After the second architectural review, we began the process of integrating the separate pieces of
our project into a single cohesive unit.
At the same time, we were documenting both the software and the project's story. Having a function
minimum viable product (MVP) and enough supporting documents for others to understand our work were our
goals for the final stretch.
The video below is a demonstration of how the camera stream is recorded via web app and then displays a
primitive heat map from where the object was; this will succeed with any footage stream.
Results
Using footage from the Weissman Foundry Fashion Show, we created a heat map outlining where individuals
clustered around the most.There are two visuals, the video immediately below shows object tracking &
heat mapping.
The video below shows the object tracking script able to successfully track and follow people along the
catwalk. Additionally, the script shows how far it can detect individuals as well as its limiations with
picking out people in a crowd. The number indicates the percent confindence such as .78 or .99.
Using this tracking video, we were then able to create a heat map feature utilizing the web app, and will
appear below.
How To Use
So, you may be wondering, how does the code work? Let's start with how to run our
app. Download our project from Github,
and run the setup script that is in the root directory. Then, execute the python
file app.py in the source directory.
git clone
https://github.com/sd19spring/the_floor_is_lava.git;
cd the_floor_is_lava
chmod +x setup.sh
./setup.sh
cd source/
python app.py
If you are using live footage from cameras connected to your computer, make sure that the cameras
are connected to your computer before you open the web app.
How to use:
# The Floor is Lava - a computer vision utility for tracking
pedestrian foot traffic
### Setup:
Clone the repository and enter the root directory of the project:
```
git clone https://github.com/sd19spring/the_floor_is_lava.git;
cd the_floor_is_lava
```
Make the setup script executable:
```
chmod +x setup.sh
```
Execute the setup script:
```
./setup.sh
```
This will install all of the dependencies for the project,
including Python modules and the yolov3.weights file that is
necessary for the person detection.
Our project makes heavy use of the following modules:
- OpenCV (opencv-python and opencv-contrib-python)
- Flask
The rest of the dependencies are listed in requirements.txt.
You may want to use a [virtual environment]
(https://realpython.com/python-virtual-environments-a-primer/)
when running the setup script.
### Usage
In the /source directory:
```
python app.py
```
A web app will open up and walk you through the rest!
### Features:
Gain a better understanding of your retail store by
visualizing how people move through your store.
- Easy to use web app
- Handles multiple cameras, and can even stitch them together
- Robust tracking using a machine learning object detection algorithm
### Examples:
*tbd*
### Authors
* Gabriella Bourdon
* Michael Remley
* Nick Bourdon
* Duncan Mazza
About
So, you may be wondering, how does the code work? Let's start with our architecture diagram:
There are important classes that were integrated and critical to the script functioning.
Below is a dense function called "get_frame" where its role is to process everything being sent to the web app. This
includes how to dim the camera, resize the camera feeds, capacity to mute camera feeds.
The function's role is also to track, measure, and create the heatmap being displayed on the screen as well as storing that information.
As you can see, this function is essentially the conductor of all of the variables moving throughout the script & organizing it on the web app.
def get_frame(self, cap_num, calibrate=False):
"""
Returns the captured frame that is warped by
the calibration_matrix
:param: cap_num - index number of the OpenCV capture
:param: calibrate - boolean for whether the frame should
be perspective corrected
:return: frame or frame converted to bytes, depending on use case
"""
# if the camera is set to off, then dim the frame by x0.2
cap = self.cap_dict.get(cap_num)[0] # select the camera
_, frame = cap.read()
# pull out the height and width of the camera frame
height = self.cap_dict[cap_num][4][0]
width = self.cap_dict[cap_num][4][1]
if self.cap_dict[cap_num][3] == 0:
# if the camera is muted
frame = frame * 0.2
return frame if self.debug else cv2.imencode
('.jpg', frame)[1].tobytes()
else:
if self.cap_dict[cap_num][1] == 1 or calibrate == True:
# if the camera is in calibration mode:
if type(self.cap_dict[cap_num][2]) != int:
# already calibrated if true; compare type because when it
# becomes the calibration matrix, the truth value
of a multi-element array is ambiguous
frame = cv2.warpPerspective(frame,self.cap_dict[cap_num][2], (height, width))
else:
# perform calibration
while self.cap_dict[cap_num][2] == 0:
# not yet calibrated
frame = self.calibrate(cap_num)
return frame if self.debug else cv2.imencode('.jpg', frame)[1].tobytes()
net = self.detect_dict[cap_num]
# select the image processor (net)
blob = cv2.dnn.blobFromImage(frame, 1 / 255.0,
self.cap_num_dict[self.num_caps],
swapRB=True, crop=False)
# pre=process the image for detection
net.setInput(blob)
# run detection on the frame:
layerOutputs = net.forward(self.ln)
boxes, frame = parse_detected(frame,
height, width, layerOutputs, self.LABELS)
# add bounding boxes to the heatmap
if self.record:
for i in range(len(boxes)):
print('cv_classes: ', cap_num)
self.heatmap.add_to_heatmap(cap_num, boxes[i])
return frame if self.debug else cv2.imencode('.jpg', frame)[1].tobytes()
Impact Statement
Introduction
We have created software with one clear intent: to provide information to retail shop owners about how
shoppers move around inside their stores so that they may arrange their store to facilitate the flow of
traffic and place products in profitable locations within the store. While this vision is not meant to
cause harm to any of the stakeholders involved, we recognize that this software could be applied to
different context or have additional consequences we did not foresee. This page serves as our
recognition of the potential ethical problems surrounding our software and describes how we expect it to
be used.
Ethics of Video Recording
We feel that it is unethical to record someone without their consent; however, it is lawful in many U.S.
states to record without consent.
That said, the footage collected for this project is video that would have existed regardless of the use
of our
product because most stores have a security system that records the store. Recording for security
purposes is common knowledge,
thanks in part to signs like this:
Given that people are generally aware of being recorded, we propose that signage be posted informing
them of how security footage is further used in stores that use our product. This informs them that they
are being recorded and to what extent that footage is used beyond what they already know. In this
fashion,
we feel we have sufficiently mitigated the ethical risks of using recorded footage of people whose
consent is only implied.
Ethics of Recognition
First and foremost, our software does not intend to identify people or create personally identifiable
information. Second, recognition softwares have historically encountered problems with diversity and
inclusion because they were published before their limitations were fully understood. As it stands now,
our software carries all the limitations of the recognition dataset from which it was trained, and we
have not yet characterized its ability to accurately recognize people who have darker skin, are
wheelchair bound, or otherwise different in physical appearance to a camera. We plan to gather this
information to prevent blind trust in our algorithm, but also recognize that our software may not have a
wide enough impact for these limitations to become significant.
Just in case,this software has not been shown to inclusively recognize people with all physical
appearances and any application must recognize this limitation.
Conclusion
To summarize, we foresee risks relating to recording shoppers and recognizing people of all kinds in the
application of our software.
We recognize that there may be other consequences that we have not foreseen, but do not expect our
software to be so widely applied that these miscomings cause widespread harm.
This is bold and this is strong. This is italic and this is emphasized.
This is superscript text and this is subscript text.
This is underlined and this is code: for (;;) { ... }. Finally, this
is a link.
Heading Level 2
Heading Level 3
Heading Level 4
Heading Level 5
Heading Level 6
Blockquote
Fringilla nisl. Donec accumsan interdum nisi, quis tincidunt felis sagittis eget tempus
euismod. Vestibulum ante ipsum primis in faucibus vestibulum. Blandit adipiscing eu felis iaculis
volutpat ac adipiscing accumsan faucibus. Vestibulum ante ipsum primis in faucibus lorem ipsum dolor
sit amet nullam adipiscing eu felis.
Preformatted
i = 0;
while (!deck.isInOrder()) {
print 'Iteration ' + i;
deck.shuffle();
i++;
}
print 'It took ' + i + ' iterations to sort the deck.';